November 2, 2023 Universal data collection for AI training with Geolancer Artificial Intelligence (AI) is rapidly transforming industries, from healthcare to finance,... Read More
October 19, 2023 Eliminating bias from AI datasets: The imperative and how Quadrant helps In the modern world, Artificial Intelligence (AI) is being leveraged across various industries to... Read More
August 19, 2022 Server-to-Server app monetization for data supply chain transparency The location data industry is characterised by opaque supply chains, making it challenging for... Read More
February 7, 2022 Using AI to clean Personally Identifiable Information from user-generated data sets Having access to large repositories of data enables businesses to optimise operations in several... Read More
July 1, 2021 Performing Extrapolation on Location Data to Derive Relevant Insights Location data is collected from multiple sources of varying quality GPS signals from mobile... Read More
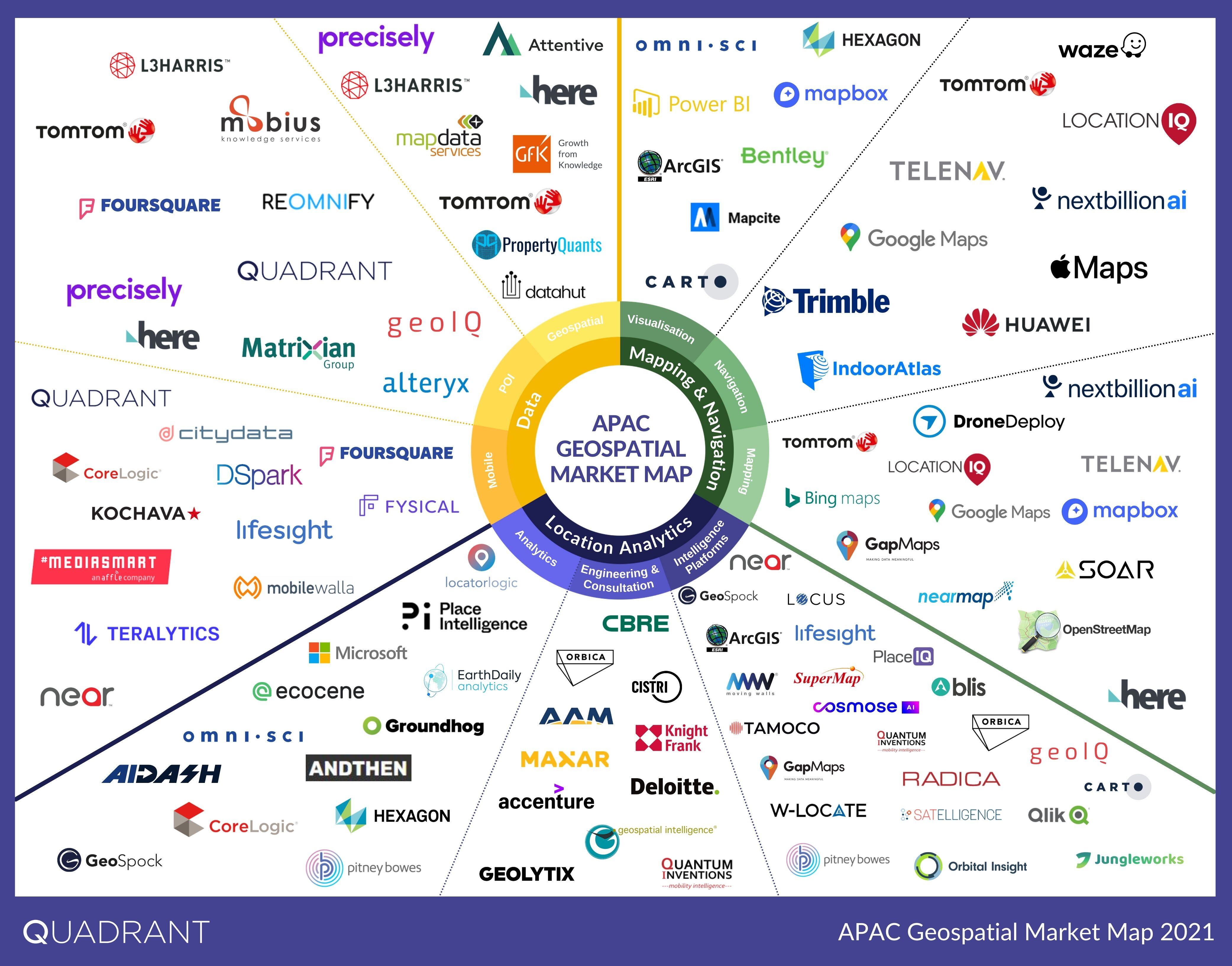
June 14, 2021 Geospatial Market Map for APAC - 2021 The intricate web of connected devices and applications produces a lot of location data. Used in... Read More
May 27, 2021 Common Problems With Location Data and How to Fix Them Geospatial data have the potential to uncover valuable insights about the physical world. It can be... Read More
March 2, 2021 Achieving Optimal Location Data Quality with Deduplication and Noise Filtering A few weeks ago, we discussed the seven most important parameters for data buyers to consider... Read More